Reinforcement learning has become the prevailing approach to humanoid locomotion control: policies transfer
reliably from simulation to hardware and recover gracefully from disturbances. Motion quality, however, still
lags behind—task-only rewards often converge to stiff, asymmetric gaits, while motion imitation methods improve
appearance but become more sensitive to external disturbances because reference signals can oppose the transient
poses needed to regain balance.
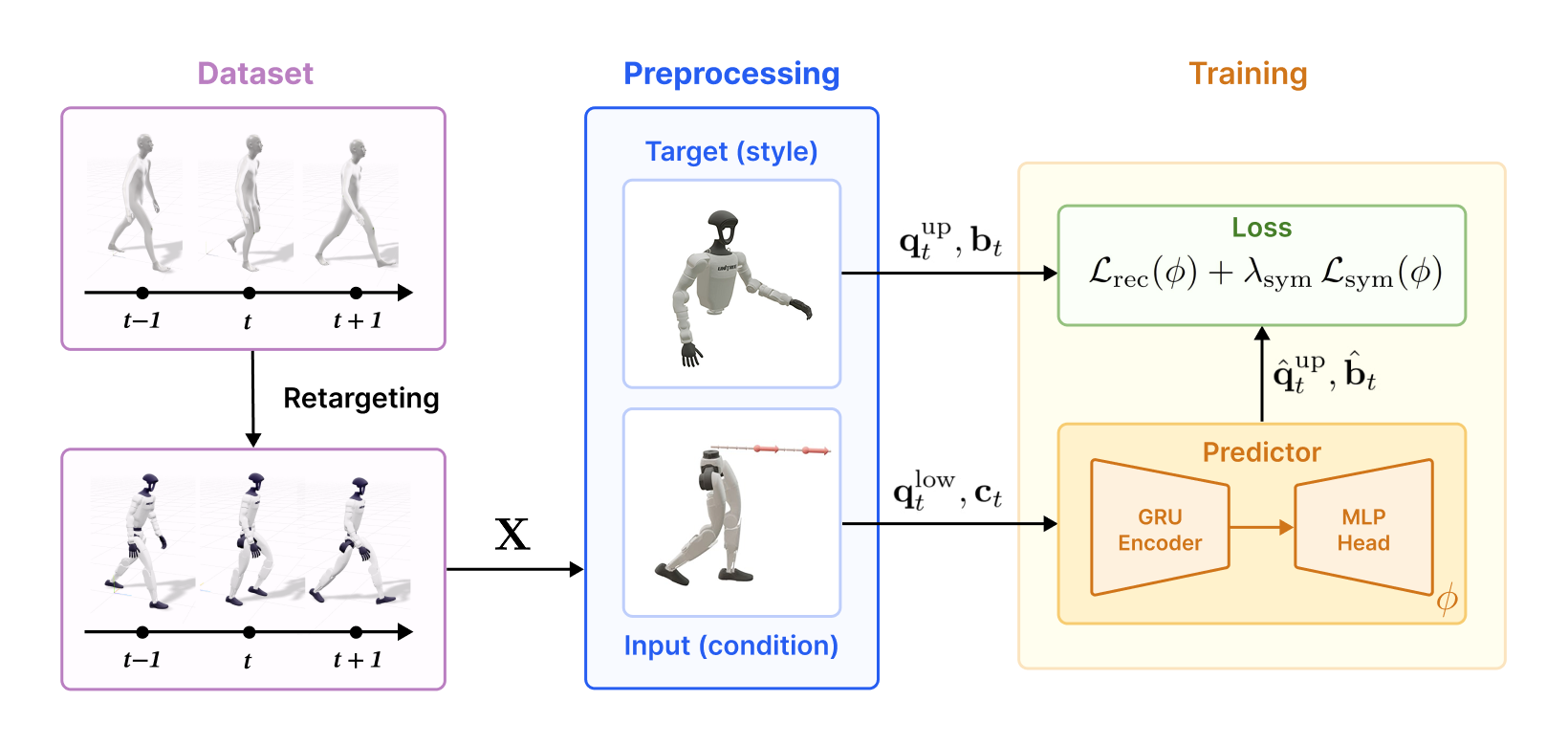
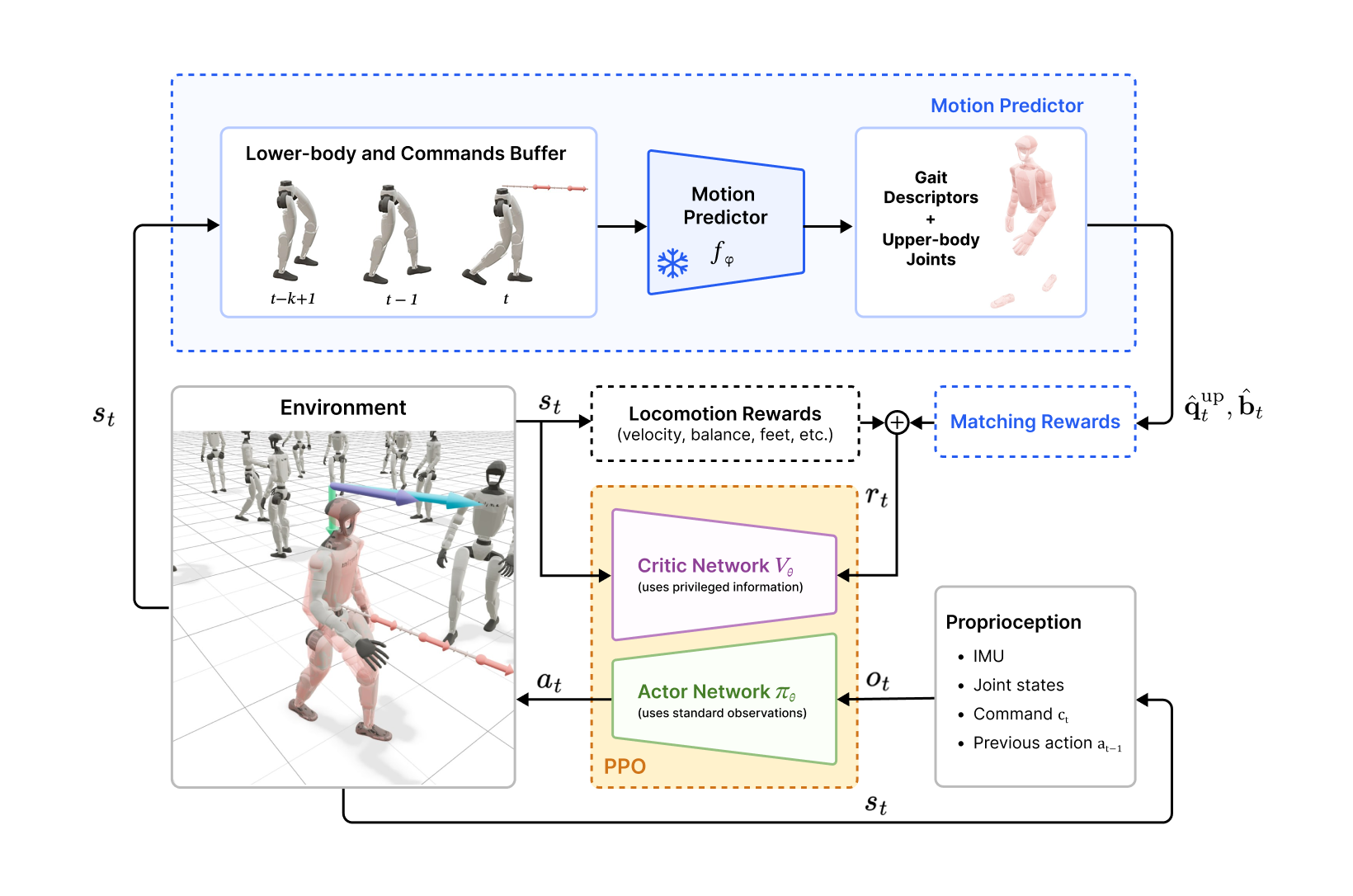
We propose Predictive Style Matching (PSM), in which an offline predictor maps the robot's
lower-body state history and velocity commands to interpretable upper-body joint and gait targets that shape
the rewards during training. Because the targets are state-conditioned rather than time-indexed and the predictor
is used only at training time, the deployed controller inherits the proprioceptive interface and inference cost
of a task-only RL baseline.
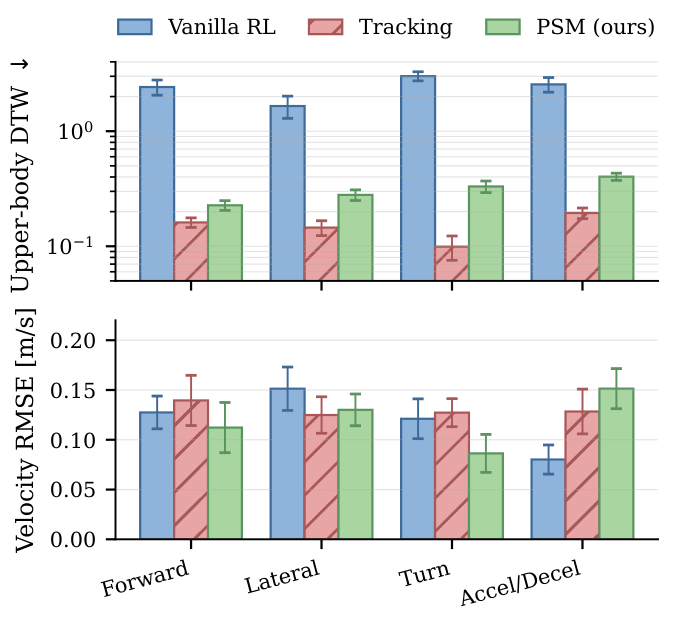
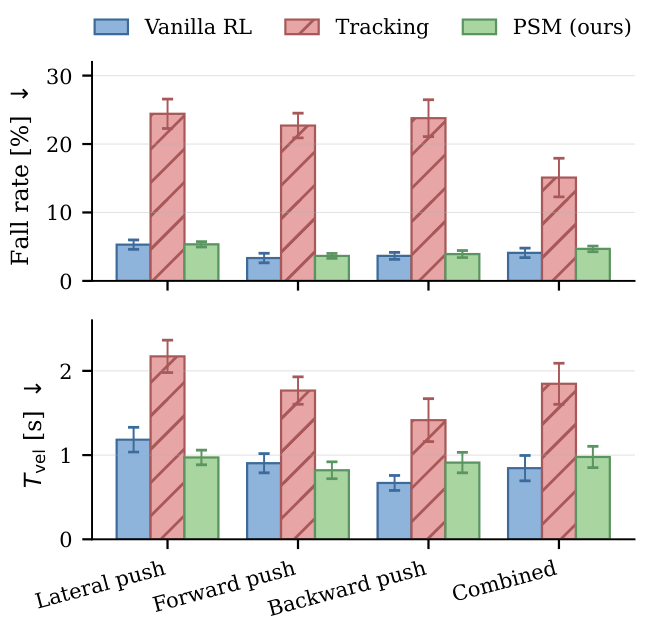
On the Unitree G1, in both simulation and hardware, PSM reduces upper-body style error by roughly an order of
magnitude over task-only RL while preserving its fall-recovery rate, whereas the motion-imitation baseline attains
the lowest style error but fails to recover from disturbances about five times as often.